What is PySpark?
PySpark allows Python users to interface with Apache Spark and wrangle data present in clusters over multiple nodes. PySpark provides users with Dataframes which is an abstraction of its underlying RDD (Resilient Distributed Datasets). PySpark supports most Spark features such as Spark SQL, dataframe, streaming, ML Lib and Spark Core.
Install PySpark
There are multiple ways of installing PySpark such as using pip , conda or manually downloading. However, the simplest way to get started is using pip install from PyPI.
pip install pysparkNote: Java installation is required for PySpark
Initialize SparkSession
SparkSession is the entry point for PySpark. It can be initialized as below
from pyspark.sql import SparkSession
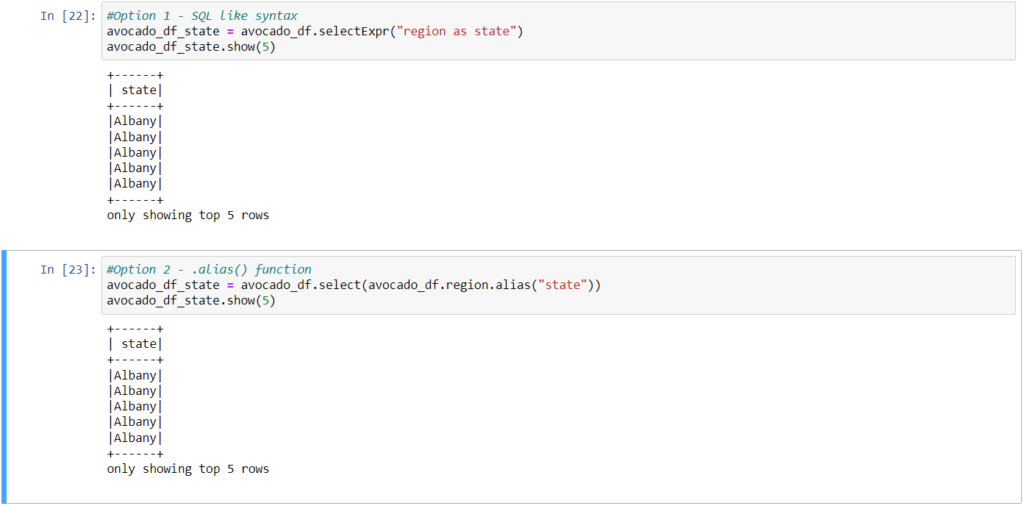
spark = SparkSession.builder.getOrCreate()Load and read CSV file
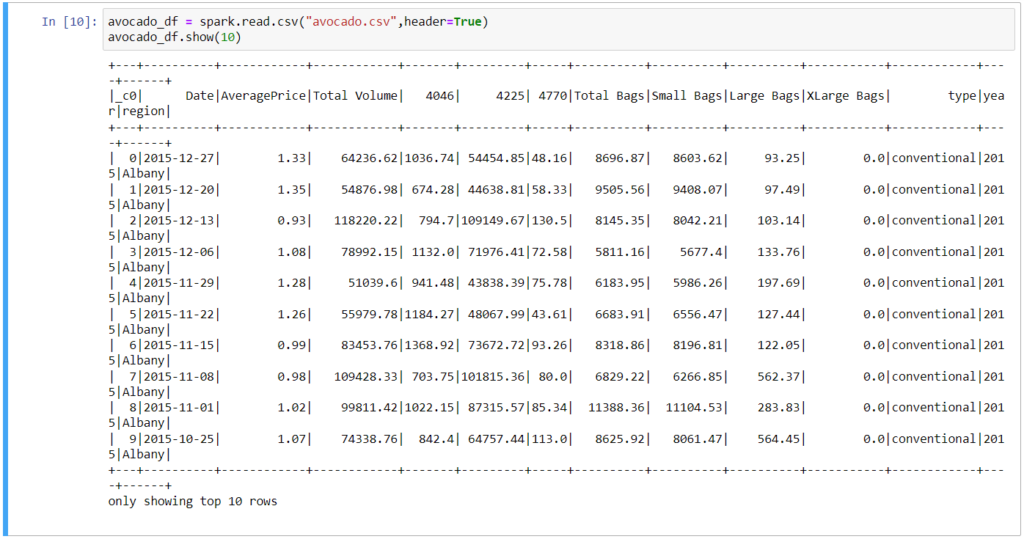
Run SQL queries on dataframe
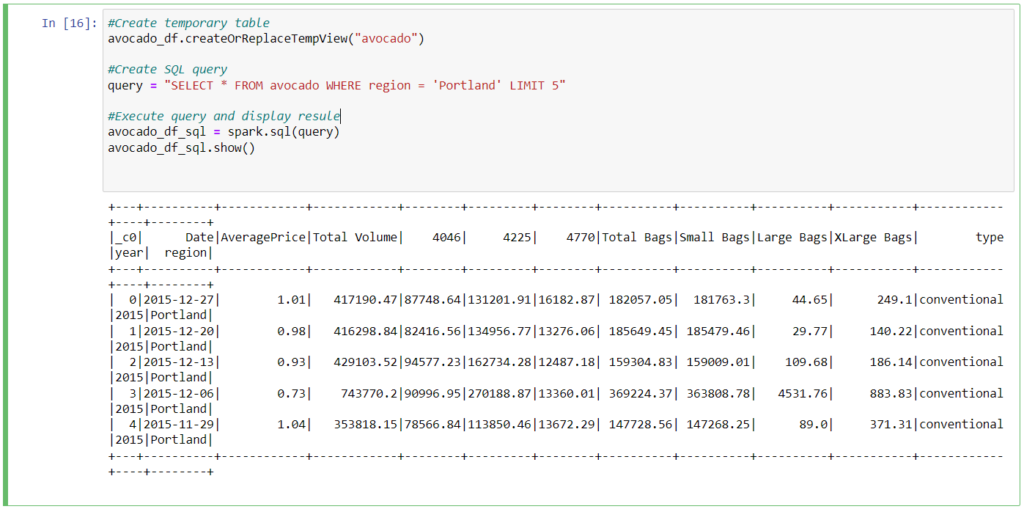
Column Operations
1. Add Column
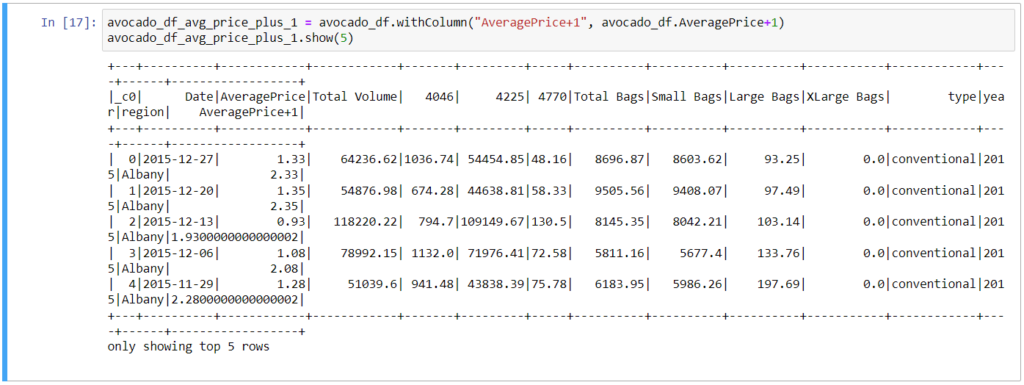
2. Select Column(s)

3. Rename Column(s)